
Contents
音響データのFFT結果を使った機械学習(Deep Learning)
1.概要
ここでは、空気圧縮機の音響データをFFT(Fast Fourier Transform)した結果を機械学習(Deep Learning)させて、空気圧縮機(エアコンプレッサ)の5つの動作状態(①待機状態、②換気状態、③圧縮状態、④排気状態、⑤排気+圧縮状態)を分類します。音響データの収集は、Arduino Nano 33 BLE Senseに搭載されているデジタルマイクロフォン“MP34DT05”を使用します。サンプリング周波数は、fs=16kHz、サンプリングデータのビット数16bit、FFTのサンプリング数1024個で行います。“MP34DT05”を使ったFFTに関しては、こちら(第6巻 4-5.デジタルマイクMP34DT05データのPDHによるFFT解析)で紹介していますので参照ください。ここでは、FFT結果の機械学習に関して説明していきます。
2.空気圧縮機の動作状態
空気圧縮機は、以下の図のような形状をしています。圧縮機で圧縮した空気はエアタンクに蓄えられ、エアフィルタを経由して各機器に供給されます。空気圧縮機は、圧力値の設定ができます。圧力値が設定値を上回っていると空気圧縮機は止まって待機しています(①待機状態)。そして、ときどき内部の換気のためにファンを回します(②換気状態)。空地が使用され、圧力が設定値を下回ると空気圧縮機が動作を開始し空気の圧縮が行われます(③圧縮状態)。空気圧縮機には、内部にたまる水を抜くためにドレンバルブが付いています。このドレンバルブを開けると内部の水を含んだ空気がドレンタンクに排気されます(④排気状態)。そのうち圧力が設定値を下回ると空気圧縮機が動作を開始します(⑤排気+圧縮状態)。
この5つの状態を機械学習で分類できるようにします。

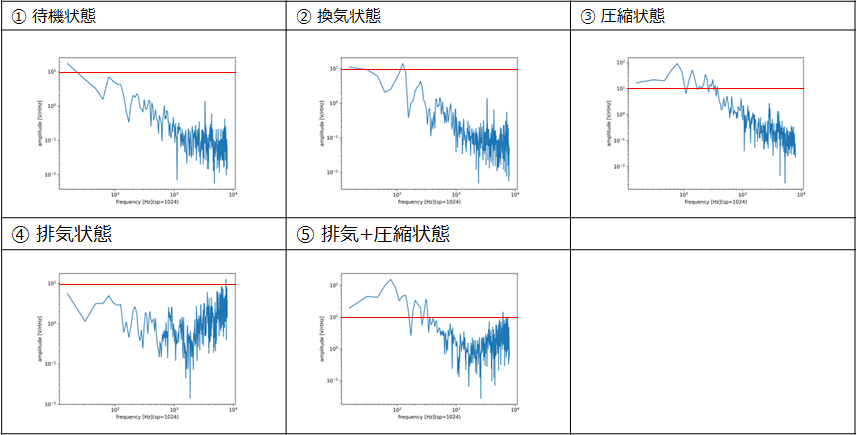
5つの状態の音響データのFFT結果を以下に示します。fs=16kHzでサンプリング数1024でFFTしていますので、周波数の区切りは16kHz/1024=15.625Hzです。
ナイキストのサンプリング定理により、16kHz÷2=8kHzが最大周波数です。DC成分は削除していますので、データ数は(1024/2) – 1 = 511です。
以下の図の赤い横線は101の目盛りにひいています。①待機状態から、②換気状態で100Hz~200Hzのレベルが盛り上がっています。④排気状態は、1kHz以上のレベルが高くなり101レベルまで上がっています。③圧縮状態では全体にレベルがあがりピークは102を超えています。⑤排気+圧縮状態では、⑤圧縮状態に1kHz以上のレベルを101レベルまで上げた形状になっています。この5つの状態を分類します。
3.機械学習(Deep Learning)
機械学習は、「ゼロから作るDeep Learning」 斎藤 康毅 著 オライリー・ジャパンを参考にしてPythonのプログラムで作成しました。以下で説明するプログラムは、この本の第5章のサンプルプログラムを流用してモディファイしています。ここでは、プログラムでモディファイしている内容についてのみ説明します。本体の説明は、本を参照してください。
3.1. ニューラルネットワークの構成
ニューラルネットワークの構成は、2層ニューラルネットワークを使用します。
入力層の数:入力層は上記のグラフのところでも説明したように、ナイキストのサンプリング定理とDCレベルを除去するため、(1024/2) – 1 = 511です。
隠れ層の数:隠れ層は書籍のままの100としています。
出力層の数:出力層は、空気圧縮機の状態の数5です(①待機状態、②換気状態、③圧縮状態、④排気状態、⑤排気+圧縮状態)。
出力は、5つの要素を持つ配列に確率値が収められて返ってきます。この中から一番大きい数字の値を持つ要素の添え字がDeep Learningの分類結果です。
パラメータは、重みとバイアスをそれぞれ、W1、b1、W2、b2としています。
活性化関数には、ReLU関数を使用しています。勾配の計算には誤差逆伝搬法を使用しています。
3.2. 訓練データ(教師データ)とテストデータの形式
Deep Learningに使用する訓練データとテストデータを準備します。訓練データとテストデータは、上記の本の内容とは異なります。上記の本では、MINISTという手書き文字のデータを使用していますが、ここでは、音響データのFFT結果を使用します。
訓練データとテストデータは、FFT結果の振幅データとこのデータがどの状態のデータなのかの情報を含んだJSONデータです。訓練データとテストデータは同じ形式ですが、用途が異なります。訓練データは、ニューラルネットワークのパラメータの更新のために使用されます。そしてテストデータは、どの程度分類がうまく行くかを確認するためのテスト用のデータです。
訓練データ(テストデータ)の形式は、以下の様な形式です。
[{“Num”:1024,“datatime”:“2023-11-28_13_11_19”,“teacher”:[1,0,0,0,0],“freq”:[15.625,31.25,・・・,7968.75, 7984.375], “amp”:[9.491911349553813,3.019656130458957,・・・, 0.08451356586143954,0.03201406963831324]},
・・・,
{"Num":1024,"datatime":"2023-12-07_08_52_54","teacher":[1,0,0,0,0],"freq":[15.625,31.25, ・・・,7968.75, 7984.375], “amp”:[13.754181045486426,10.118336580982199,・・・, 0.04267337029706663,0.030070514350138387]}]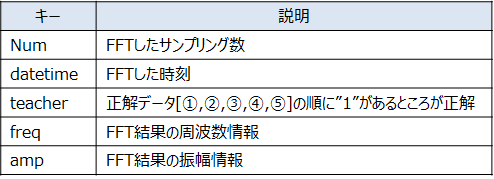
3.3. 訓練データ(教師データ)とテストデータの生成
こちら(第6巻 4-5.デジタルマイクMP34DT05データのPDHによるFFT解析)で紹介したFFTのプログラムを使ってFFTを行うと、FFT結果の画像データと数値データが以下のフォルダに出力されます。
画像データ:/home/pi/Dcouments/pdm_idu/pictures/
数値データ:/home/pi/Dcouments/pdm_idu/fftResult/
数値データは、上記のJSONデータでキー“teacher”以外は保存されています。
{“Num”:1024,“datatime”:“2023-11-28_13_11_19”, “freq”:[15.625,31.25,・・・,7968.75, 7984.375], “amp”:[9.491911349553813,3.019656130458957,・・・, 0.08451356586143954,0.03201406963831324]}したがって、画像データを見て5つの状態のどれかを人間が判断して、それに対応する数値データにキー“teacher”:[1,0,0,0,0],)を追加し、訓練データとテストデータをそれぞれ一つにまとめればOKです。
いろいろな方法があると思いますが、ここでは我々が行った方法を紹介します。考え方は、以下の通りです。
画像データと数値データのファイルには、いずれも日時がファイル名として記載されています。これを利用して、画像データと数値データのマッチングを行います。
(1)画像データを一つ一つ目視確認して、ディレクトリに分類します。
(2)分類した画像データが入っているディレクトリ名からキー”teacher”を作成し、ファイル名をキー“name”として1024.jsonファイルに保存します。これを実行する”name.csh”というシェルスクリプトを作成します。訓練データとテストデータとをそれぞれ行います。
(3)数値データは、Jason_dataというディレクトリにすべてのjson_dataを保管します。
(4)json_dataにあるファイルを1つの”all_data.json”というファイル名のファイルにまとめます。そのための”all_data.csh”というシェルスクリプトを準備します。
(5)Node-REDを使って、“all_data.json”の中のキー“datetime”の値と1024.jsonのキー”name”の値との一致を調べます。一致したら、all_data.jsonの中のデータと1024.jsonの中のキー”teacher”の値を一つのjsonファイルにマージします。訓練データの場合には、”teacher_1024.json”、テストデータの場合には、”test_1024.json”というファイル名とします。これらが、訓練データとテストデータのjsonファイルです。
以下、具体的な内容を説明します。
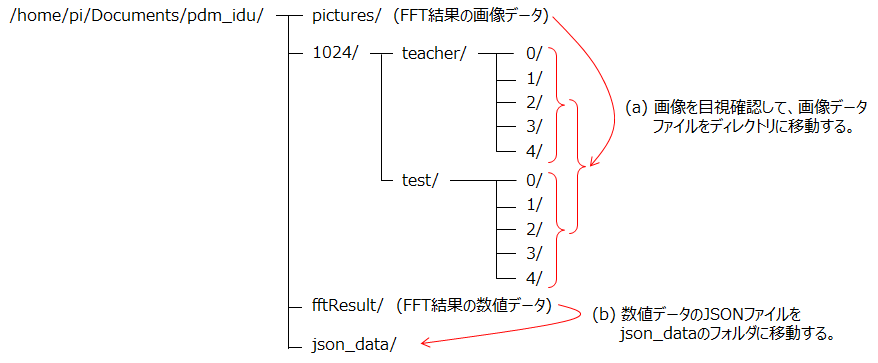
1)ディレクトリ構造
ディレクトリ構造は以下の様です。
2) 画像ファイルの分類
上記、ディレクトリ構造の/home/pi/Documents/pdm_imu/pictures/の下に収められたFFT結果の画像データを目視確認し、5つの状態のどれかを判断し、該当する以下のディレクトリに移動させる。
3)画像ファイルのjsonファイルの作成
~/Documents/pdm_imu/1024/teacher/name.cshと~/Documents/pdm_imu/1024/test/name.cshを実行します。2つのファイルは同じものです。
name.cshのファイルの中身を以下に示します。
#!/bin/bash
# 0: normal condition
ls -1 0 | sed "s/\./ /"| awk '{print "{\"name\" : \"" $1"\", \"Num\" : 1024, \"teacher\" : [1, 0, 0, 0, 0]},"}' > 1024.txt
# 1: fan operating condition
ls -1 1 | sed "s/\./ /"| awk '{print "{\"name\" : \"" $1"\", \"Num\" : 1024, \"teacher\" : [0, 1, 0, 0, 0]},"}' >> 1024.txt
# 2: complessor operating condition
ls -1 2 | sed "s/\./ /"| awk '{print "{\"name\" : \"" $1"\", \"Num\" : 1024, \"teacher\" : [0, 0, 1, 0, 0]},"}' >> 1024.txt
# 3: drain open condition
ls -1 3 | sed "s/\./ /"| awk '{print "{\"name\" : \"" $1"\", \"Num\" : 1024, \"teacher\" : [0, 0, 0, 1, 0]},"}' >> 1024.txt
# 4: complessor operating condition
ls -1 4 | sed "s/\./ /"| awk '{print "{\"name\" : \"" $1"\", \"Num\" : 1024, \"teacher\" : [0, 0, 0, 0, 1]},"}' >> 1024.txt
wc 1024.txt
sed -z "s/\n/ /g" 1024.txt | sed "s/^/{\"label\":\[/" | sed "s/, $/\]}/" > 1024.json1行目:bashを起動します。
3行目:ディレクトリ0~4の下のファイルを“ls -1”で表示させます。そして”sed”を使ってファイル名と拡張子の間のピリオド”.”を空白“ ”に置き換えます。
ディレクトリ0にあるファイルであれば、①待機状態の画像なので、キー”teacher”:[1,0,0,0,0]とキー“name”にファイル名を追加した1024.txtファイルを作ります。
6,9,12,15行目:ディレクトリ1~4も同様な処理を行います。正解データは、ディレクトリ毎に変えます。ディレクトリ1~4の場合は、リダイレクトを”>>”にしてファイルに追記とします。
17行目:“wc”コマンドで行数(すなわちデータ数)を確認します。
19行目:最後に、1024.txtの内容をキー”label”の配列データとしてjsonフォーマットに変更します。具体的には、1024.txtの改行コードを削除して1行に変換し、行頭と行末にそれぞれ{”label”:[, ]}を追加します。
4) 数値データのファイル移動
FFT結果の数値データファイルを~/Documents/pdm_imu/fftResult/から~/Documents/pdm_imu/json_data/に移動します。
5)数値データファイルを1つのファイルにマージする
~/Documents/pdm_imu/json_data/all_data.cshを実行します。
シェルの中身を以下に示します。個別のjsonファイルをキー“data”の下の配列データにして、all_data.jsonにまとめます。
#!/bin/bash
cat *.json | sed "s/^/\{\"data\"\:\[/" | sed "s/$/\]\}/"| sed "s/}{/},{/g" > all_data.json1行目:bashを実行します。
2行目:catですべてのjsonファイルを順番に読み込みます。この時点で1行になっていますので、行頭に{“data”:[を追加します。そして行末には、]を追加します。最後に、すべての中括弧“}{”の間にカンマを追加し“},{”とします。再度にall_data.jsonに上書きします。
5) Node-REDを使って、画像データと数値データをマッチングする
上記で作成した画像データの訓練データとテストデータの1024.jsonと数値データのall_data.jsonをマッチングして訓練データとテストデータを作成します。フローを以下に示します(フローのjsonファイルはAppendix.1に掲載しています)。一番上の列が、all_data.jsonを読み込み、“flow.data”に読み込む動作をします。一番初めに実行します(injectボタンを押す) 。
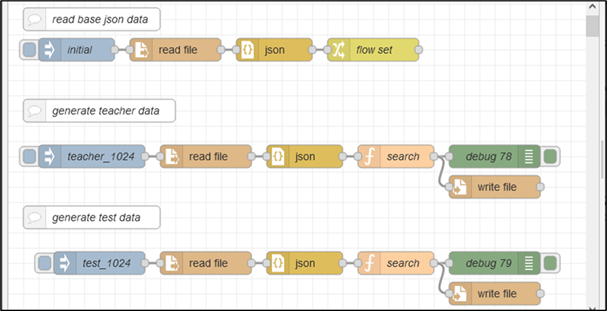
2番目と3番目は、teacherデータかtestデータかの違いでやっていることは同じです。1024.jsonを読み込んで、1つずつキー”name”が、all_data.jsonのキー“datetime”と一致するかをチェックします。一致したら、all_data.jsonの数値データと1024.jsonのキー”teacher”とを一つのファイルにして、teacher_1024.jsonもしくはtest_1024.jsonに書き出します。以下、functionノードの中身を説明します。
var data = flow.get("data");
var label = msg.payload.label;
var data_size = data.length;
var label_size = label.length;
let out_data = [];
for (var i=0; i<label_size; i++){
for (var j=0; j<data_size; j++){
if (label[i].name == data[j].datatime){
if (label[i].Num == data[j].Num){
let new_object = {};
new_object.Num = label[i].Num;
new_object.datatime = data[j].datatime;
new_object.teacher = label[i].teacher;
new_object.freq = data[j].freq;
new_object.amp = data[j].amp;
out_data.push(new_object);
} else {
node.warn("転送サイズが合いません: ");
node.warn(label[i].name);
}
continue;
}
}
}
msg.payload = out_data;
return msg;
・ var data = flow.get(“data”);
flow.dataの値(all_data.json)を変数dataに読み込みます。
・ var label = msg.payload.label;
msg.payload.labelの値(1024.json)を変数labelに読み込みます。
・ var data_size = data.length;
var label_size = label.length;
dataとlabelのデータ数をそれぞれ変数data_sizeとlabel_sizeに格納します。
・ let out_data = [];
出力データ用の空の配列オブジェクトを準備します。
・ for (var i=0; i<label_size; i++){
// labelデータを一つずつ処理します。
for (var j=0; j<data_size; j++){
// dataを一つずつ呼び出します。
if (label[i].name == data[j].datatime){
// labelのnameとdataのdatatimeが一致したら以下を実行します。
// 一致しなかったら次に行きます。
if (label[i].Num == data[j].Num){
// labelのNumとdataのNumが一致したら、以下を実行。
let new_object = {};
// 空のオブジェクトを準備
new_object.Num = label[i].Num;
new_object.datatime = data[j].datatime;
new_object.teacher = label[i].teacher;
new_object.freq = data[j].freq;
new_object.amp = data[j].amp;
// nw_objectにデータを代入します。
out_data.push(new_object);
// 出力用配列に追加します。
} else {
// labelのNumとdataのNumが一致しないのでエラーメッセージ表示
node.warn(“転送サイズが合いません: “);
node.warn(label[i].name);
}
continue;
// 次に移動します。
}
}
}
3.4. 訓練データとテストデータの読込み
参考にした「ゼロから作るDeep Learning」の本は、MNISTデータを独自のpythonプログラムで、Deep Learningのpythonプログラムに読み込ませています。
今回作成したFFTの訓練データとテストデータをサンプルプログラムで使用できるように、訓練データとテストデータを読み込ませるプログラムを作成しました。
以下、説明します。
サンプルプログラムでは、以下の一文でデータを読み込んでいます。
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)そこで、この関数の代わりに、以下の様な関数を作成しました。
(x_train, t_train), (x_test, t_test) = load_fft()中身は簡単で、teacher_1024.jsonとtest_1024.jsonをそれぞれ読み込んで、キー“amp”とキー“teacher”をそれぞれnumpy配列に変換して、リストとして返しています。以下に、プログラム”load_fft_1024.py”を載せています。このプログラムは後述する”train_neuralnet_1024.py”から呼び出されます。
import json
import numpy as np
# ファイル名
filename1 = '/home/pi/Documents/pdm_imu/1024/teacher_1024.json'
filename2 = '/home/pi/Documents/pdm_imu/1024/test_1024.json'
def load_fft():
# teacherとtestの配列を作成
train_data = []
train_label = []
test_data = []
test_label = []
# ファイルを開く
with open(filename1, 'r') as f:
# JSONデータを読み込む
items = json.load(f)
for item in items:
train_data.append(item['amp'])
train_label.append(item['teacher'])
# ファイルを開く
with open(filename2, 'r') as f:
# JSONデータを読み込む
items = json.load(f)
for item in items:
test_data.append(item['amp'])
test_label.append(item['teacher'])
# リストをnumpy配列に変換
train_data = np.array(train_data)
train_label = np.array(train_label)
test_data = np.array(test_data)
test_label = np.array(test_label)
print('train_data :', train_data.shape)
print('train_label:', train_label.shape)
print('test_data :', test_data.shape)
print('test_label:', test_label.shape)
return (train_data, train_label), (test_data, test_label)3.6. ミニバッチ学習の実行
上記で作成した学習データを用いて、ミニバッチ学習を行います。
訓練データ数:799
テストデータ数:27
バッチ数:100
学習レート:0.01
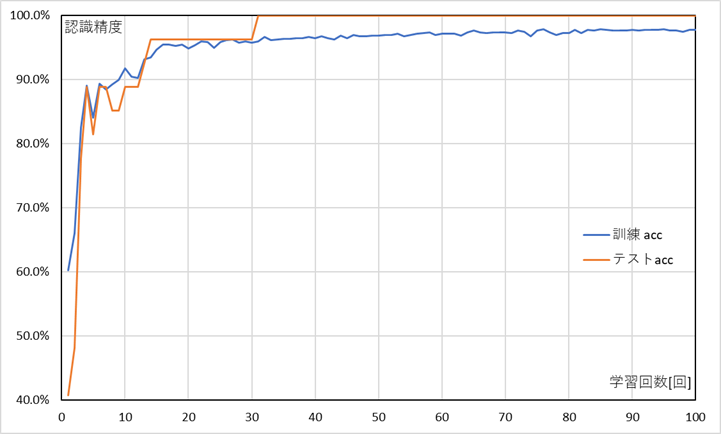
この条件で学習を行った結果を以下に示します。
青の線が、訓練データの認識精度でオレンジがテストデータの認識精度です。訓練データの認識精度は徐々に上がっていき97%程度まで上がりました。テストデータは30回過ぎで100%分類できるようになりました。
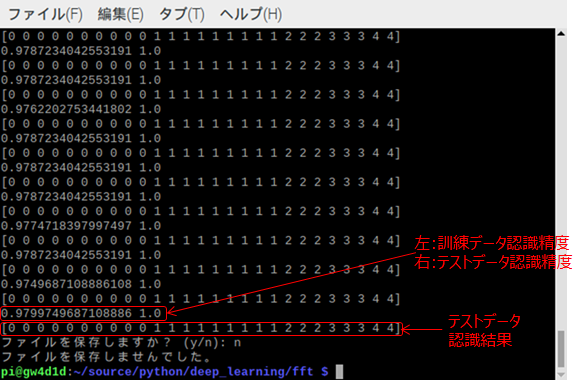
以下の実行画面に示すように、0~4の状態が正しく分類できています。
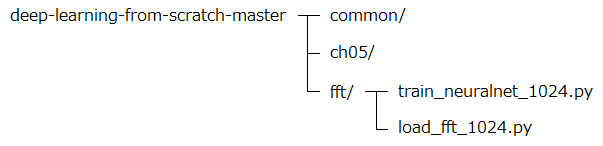
実行時には、以下の様なディレクトリ構成にしてください。ディレクトリ”ch05”と”common”は、参考本のサンプルプログラムのディレクトリです。
実行時は、fftのディレクトリに入り、以下のコマンドを実行してください。最後にファイルを保存するか聞いてくるので、学習したパラメータを保存する場合は’y’を、保存しない場合は’n’を入力して、プログラムを終了させてください。
python3 train_neuralnet_1024.py参考本のサンプルプログラム“chap05\train_neuralnet.py”から、ミニバッチ学習のプログラム“train_neuralnet_1024.py”の変更点を説明します。
次に、プログラム“train_neuralnet_1024.py”を示します。このプログラムの中で、元のサンプルプログラムとの異なる部分を説明します。元のプログラムと異なる部分は赤字にしています。
・ import pickle
機械学習した結果のパラメータを保存するためのpickleライブラリをインポートします。
・ import math
小数点以下切り捨てのmath.floor()関数を使用するために、mathライブラリをインポートします。
・ from load_fft_1024 import load_fft
(x_train, t_train), (x_test, t_test) = load_fft()
fft結果の学習データを読み込むための関数load_fft()を読み込みます。
・ from ch05.two_layer_net import TwoLayerNet
参考本のch05ディレクトリにあるtwo_layer_net.pyの中のTwoLayerNetを読み込みます。
・ network = TwoLayerNet(input_size=511, hidden_size=100, output_size=5)
入力層の数=511, 隠れ層の数=100, 出力層の数=5に変更します。
・ iters_num = 799
batch_size = 100
learning_rate = 0.01
訓練データ数:799、バッチ数:100、学習レート:0.01に設定します。
・ iter_per_epoch = max(math.floor(train_size / batch_size), 1)
train_size/batch_sizeが整数になるようにmath.floor関数を使って小数点以下を切り捨てます(正確には、math.floor関数は与えられた数値以下の最大の整数を返します)。
・ y=network.predict(x_test)
y = np.argmax(y, axis=1)
print(y)
テストデータの認識結果を表示させます。TwoLayerNetのpredict()関数を呼んで、テストデータの認識を行わせています。そして、np.argmax()関数を使って、最大確率を取得した添え字を選び、printします。この部分は元のプログラムにはありません。
・ # ユーザーにキー入力を求める
key = input(‘ファイルを保存しますか? (y/n): ‘)
# 入力が ‘y’ の場合、ファイルを保存する
if key.lower() == ‘y‘:
with open(‘params_1024.pkl’, ‘wb’) as f:
pickle.dump(network.params, f)
print(‘ファイルを保存しました。‘)
# 入力が ‘n’ の場合、保存しない
elif key.lower() == ‘n‘:
print(‘ファイルを保存しませんでした。‘)
# それ以外の入力の場合、エラーメッセージを表示する
else:
print(‘無効な入力です。”y” または “n” を入力してください。‘)
パラメータを保存するかどうかのキー入力を要求します。
yを入力すると”params_1024.pkl”というファイル名にバイナリでパラメータを書き出します。
nを入力すると、保存はされず終了します。
どちらでもない入力をすると、「無効な入力です。」と表示して終了します。
# coding: utf-8
import sys, os
import pickle
import math
sys.path.append(os.pardir)
import numpy as np
from load_fft_1024 import load_fft
from ch05.two_layer_net import TwoLayerNet
# データの読み込み
(x_train, t_train), (x_test, t_test) = load_fft()
# fft data as 1024
network = TwoLayerNet(input_size=511, hidden_size=100, output_size=5)
iters_num = 799
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(math.floor(train_size / batch_size), 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 勾配
#grad = network.numerical_gradient(x_batch, t_batch)
grad = network.gradient(x_batch, t_batch)
# 更新
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(train_acc, test_acc)
y=network.predict(x_test)
y = np.argmax(y, axis=1)
print(y)
# ユーザーにキー入力を求めるkんjhyhjぎゅy67tfdcx
key = input('ファイルを保存しますか? (y/n): ')
# 入力が 'y' の場合、ファイルを保存する
if key.lower() == 'y':
with open('params_1024.pkl', 'wb') as f:
pickle.dump(network.params, f)
print('ファイルを保存しました。')
# 入力が 'n' の場合、保存しない
elif key.lower() == 'n':
print('ファイルを保存しませんでした。')
# それ以外の入力の場合、エラーメッセージを表示する
else:
print('無効な入力です。"y" または "n" を入力してください。')Appendix.1 教師データ作成用Node-REDのフロー
次に、本文の「5) Node-REDを使って、画像データと数値データをマッチングする」で説明したNode-REDのフローを掲載します。
[{"id":"c5f7b408a6c0e423","type":"tab","label":"teacherData","disabled":false,"info":"","env":[]},{"id":"89cf68353c91e3d3","type":"file in","z":"c5f7b408a6c0e423","name":"","filename":"filename","filenameType":"msg","format":"lines","chunk":false,"sendError":false,"encoding":"none","allProps":false,"x":220,"y":100,"wires":[["39eefac94f220976"]]},{"id":"1e3a48280ca5d32e","type":"inject","z":"c5f7b408a6c0e423","name":"initial","props":[{"p":"filename","v":"/home/pi/Documents/pdm_imu/json_data/all_data.json","vt":"str"},{"p":"topic","vt":"str"}],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","x":90,"y":100,"wires":[["89cf68353c91e3d3"]]},{"id":"39eefac94f220976","type":"json","z":"c5f7b408a6c0e423","name":"","property":"payload","action":"","pretty":false,"x":350,"y":100,"wires":[["59b048aeefd836e9"]]},{"id":"ed39c18b739d3be4","type":"debug","z":"c5f7b408a6c0e423","name":"debug 78","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":640,"y":240,"wires":[]},{"id":"d8d09da6c8669a08","type":"inject","z":"c5f7b408a6c0e423","name":"teacher_1024","props":[{"p":"filename","v":"/home/pi/Documents/pdm_imu/1024/teacher_data/1024.json","vt":"str"},{"p":"topic","vt":"str"}],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"/home/pi/Documents/pdm_imu/1024/teacher_1024.json","x":110,"y":240,"wires":[["0be81774359513d2"]]},{"id":"59b048aeefd836e9","type":"change","z":"c5f7b408a6c0e423","name":"flow set","rules":[{"t":"move","p":"payload.data","pt":"msg","to":"data","tot":"flow"}],"action":"","property":"","from":"","to":"","reg":false,"x":480,"y":100,"wires":[[]]},{"id":"4b0c3622ddc46d7d","type":"function","z":"c5f7b408a6c0e423","name":"search","func":"var data = flow.get(\"data\");\nvar label = msg.payload.label;\nvar data_size = data.length;\nvar label_size = label.length;\nlet out_data = [];\nfor (var i=0; i<label_size; i++){\n for (var j=0; j<data_size; j++){\n if (label[i].name == data[j].datatime){\n if (label[i].Num == data[j].Num){\n let new_object = {};\n new_object.Num = label[i].Num;\n new_object.datatime = data[j].datatime;\n new_object.teacher = label[i].teacher;\n new_object.freq = data[j].freq;\n new_object.amp = data[j].amp;\n out_data.push(new_object);\n } else {\n node.warn(\"転送サイズが合いません: \");\n node.warn(label[i].name);\n }\n continue;\n }\n }\n}\nmsg.payload = out_data;\nreturn msg;\n","outputs":1,"noerr":0,"initialize":"","finalize":"","libs":[],"x":510,"y":240,"wires":[["ed39c18b739d3be4","a9d7704a1aa40d84"]]},{"id":"0be81774359513d2","type":"file in","z":"c5f7b408a6c0e423","name":"","filename":"filename","filenameType":"msg","format":"lines","chunk":false,"sendError":false,"encoding":"none","allProps":false,"x":260,"y":240,"wires":[["c356c72869cafd45"]]},{"id":"c356c72869cafd45","type":"json","z":"c5f7b408a6c0e423","name":"","property":"payload","action":"","pretty":false,"x":390,"y":240,"wires":[["4b0c3622ddc46d7d"]]},{"id":"a9d7704a1aa40d84","type":"file","z":"c5f7b408a6c0e423","name":"","filename":"topic","filenameType":"msg","appendNewline":true,"createDir":false,"overwriteFile":"true","encoding":"none","x":640,"y":280,"wires":[[]]},{"id":"870b3300077050b9","type":"comment","z":"c5f7b408a6c0e423","name":"read base json data","info":"","x":110,"y":60,"wires":[]},{"id":"9bacdbf0d42887da","type":"comment","z":"c5f7b408a6c0e423","name":"generate teacher data","info":"","x":120,"y":180,"wires":[]},{"id":"c94ef4abea16aae7","type":"file in","z":"c5f7b408a6c0e423","name":"","filename":"filename","filenameType":"msg","format":"lines","chunk":false,"sendError":false,"encoding":"none","allProps":false,"x":260,"y":380,"wires":[["1549d995bb326a87"]]},{"id":"4b9085b5f2e42ce7","type":"inject","z":"c5f7b408a6c0e423","name":"test_1024","props":[{"p":"filename","v":"/home/pi/Documents/pdm_imu/1024/test_data/1024.json","vt":"str"},{"p":"topic","vt":"str"}],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"/home/pi/Documents/pdm_imu/1024/test_1024.json","x":120,"y":380,"wires":[["c94ef4abea16aae7"]]},{"id":"1549d995bb326a87","type":"json","z":"c5f7b408a6c0e423","name":"","property":"payload","action":"","pretty":false,"x":390,"y":380,"wires":[["ede1798fe0675c23"]]},{"id":"ede1798fe0675c23","type":"function","z":"c5f7b408a6c0e423","name":"search","func":"var data = flow.get(\"data\");\nvar label = msg.payload.label;\nvar data_size = data.length;\nvar label_size = label.length;\nlet out_data = [];\nfor (var i=0; i<label_size; i++){\n for (var j=0; j<data_size; j++){\n if (label[i].name == data[j].datatime){\n if (label[i].Num == data[j].Num){\n let new_object = {};\n new_object.Num = label[i].Num;\n new_object.datatime = data[j].datatime;\n new_object.teacher = label[i].teacher;\n new_object.freq = data[j].freq;\n new_object.amp = data[j].amp;\n out_data.push(new_object);\n } else {\n node.warn(\"転送サイズが合いません: \");\n node.warn(label[i].name);\n }\n continue;\n }\n }\n}\nmsg.payload = out_data;\nreturn msg;\n","outputs":1,"noerr":0,"initialize":"","finalize":"","libs":[],"x":510,"y":380,"wires":[["cbcd57d128a3ea70","d1a032c78e1ac1f1"]]},{"id":"cbcd57d128a3ea70","type":"debug","z":"c5f7b408a6c0e423","name":"debug 79","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":640,"y":380,"wires":[]},{"id":"d1a032c78e1ac1f1","type":"file","z":"c5f7b408a6c0e423","name":"","filename":"topic","filenameType":"msg","appendNewline":true,"createDir":false,"overwriteFile":"true","encoding":"none","x":640,"y":420,"wires":[[]]},{"id":"0cbd73200a4a5cff","type":"comment","z":"c5f7b408a6c0e423","name":"generate test data","info":"","x":110,"y":320,"wires":[]}]